
Stack choices determine whether an AI platform ships quickly, passes security reviews, and scales with predictable cost. Over the last three years we tested Python/FastAPI, Ruby on Rails, Node/Express, Remix, Astro, and Cloudflare-native stacks. The combination that consistently wins enterprise deals is Next.js + Supabase + Vercel with OpenAI/Anthropic for inference and PostHog for observability.
This guide explains why we standardized on that stack, how the pieces fit together, and when to choose alternatives. It’s the architecture we use on Next.js AI platform engagements where RAG, multi-tenant security, and agent workflows must co-exist without leaking data or blowing up costs.
It’s also tuned for Retrieval-Augmented Generation (RAG) workloads that rely on both semantic search and keyword fallbacks-letting you combine vector search with deterministic lookups without changing the core stack.
Complete tech stack for modern AI platform development.
1. Selection criteria: what we optimize for
Before discussing frameworks, we score stacks against five requirements:
- Security-first multi-tenancy - Native support for Row-Level Security (RLS), org switching, and tenant-scoped caches without duct tape. (See multi-tenant SaaS security patterns for the DB layer.)
- AI ergonomics - Streaming responses, Server Actions, edge-friendly APIs, and easy integration with OpenAI/Anthropic/Vertex. (Pairs with RAG architecture and semantic search when retrieval matters.)
- Velocity - shadcn/ui, Tailwind, Turbopack, and reusable components shorten the feedback loop without forcing proprietary tools.
- Observability & billing - Built-in analytics hooks (PostHog, Sentry) and reliable usage metering for tokens and API calls. (For security testing the stack, see AI penetration testing methodology.)
- Deployment discipline - Immutable previews, environment secrets, zero-trust networking, and fast rollbacks.
Next.js + Supabase + Vercel scores highest across those criteria for B2B SaaS teams shipping AI copilots, analytics portals, and agent automation. Let’s break down each layer.
See Also
- AI Platform Security Guide - full system-wide architecture
- AI Agent Architecture - tool orchestration & guardrails
- LLM Security Guide - LLM-specific threat modeling
- Penetration Testing AI Platforms - how AI products are tested
- Multi-Tenant SaaS Architecture - tenant isolation & RLS
- RAG Architecture Guide - retrieval and semantic search
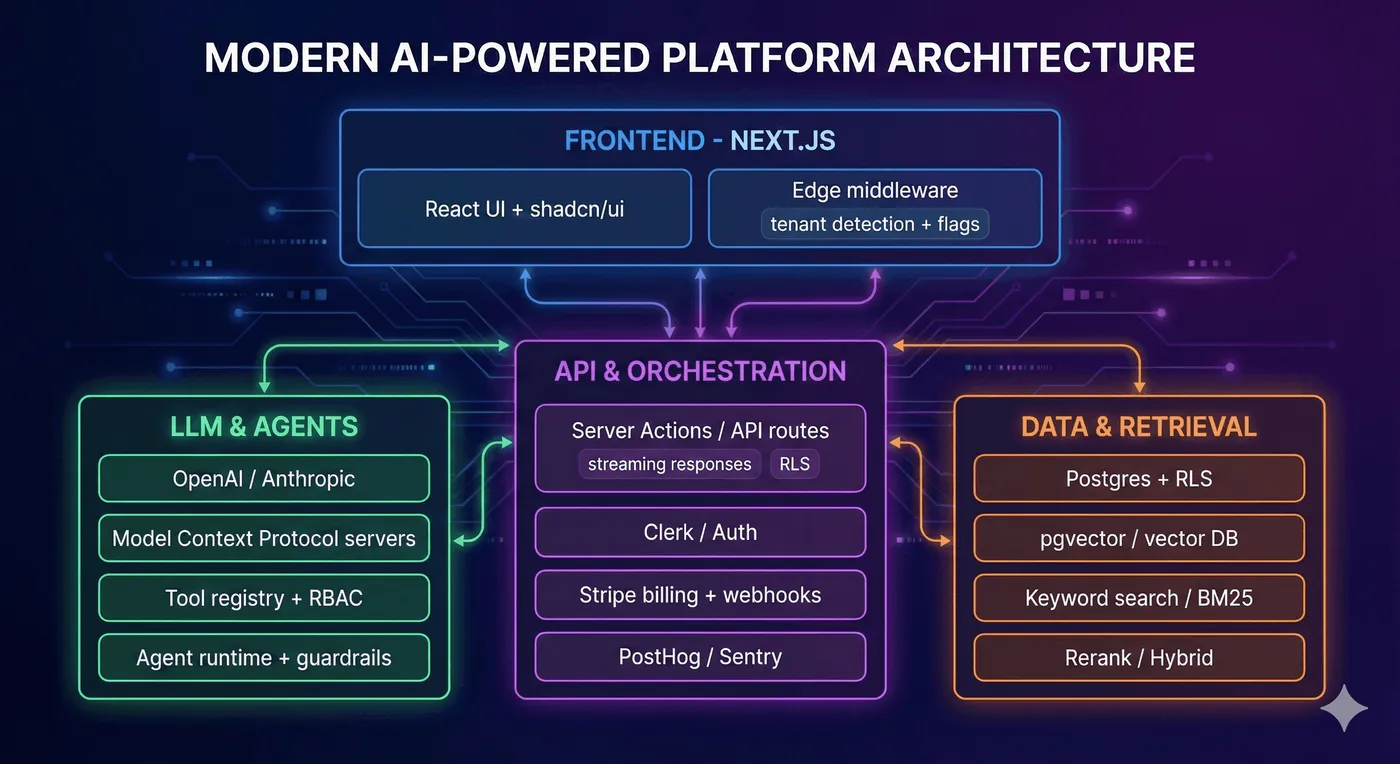
2. Stack breakdown
Tech stack diagram (high level)

2.1 Frontend & experience layer (Next.js + shadcn/ui)
| Component | Why we use it | Trade-offs / alternatives |
|---|---|---|
| Next.js 16 (App Router, Server Components, Turbopack) | Streaming AI responses, colocated data fetching, and flexible deployment targets (Edge + Node). | Requires TypeScript discipline; React-specific hiring pool. |
| shadcn/ui + Tailwind CSS | Consistent design system + rapid prototyping with composable primitives. | Requires attention to accessibility; add tests to prevent divergent variants. |
| Lucide + custom SVGs | Lightweight iconography that pairs with AI storytelling. | Teams preferring Material Icons can swap without architectural impact. |
Key patterns
- Server Components for AI streaming: fetch embeddings or LLM responses server-side, stream via
use serveractions to prevent exposing API keys in the browser. - Edge middleware: handle tenant detection and feature flags before rendering to cut down waterfall latency.
- shadcn tokens: co-locate component variants with feature folders (hero, dashboard, chat) so design updates propagate without rewriting entire pages.
Alternatives
- Remix / Hydrogen: great for commerce-first experiences but lacks the out-of-the-box server component ergonomics we need for AI streaming.
- Astro: still part of our marketing stack, but for authenticated apps with real-time updates, Next.js wins.
2.2 Backend & database layer (Supabase + Postgres + pgvector)
Supabase ships Postgres, pgvector, Auth, Storage, and Edge Functions in one control plane. We pair it with Neon or RDS when clients need dedicated VPCs, but Supabase handles most SaaS scenarios.
Why Postgres
- RLS enforcement with policies scoped to
app.current_tenant. - JSONB columns for flexible metadata (prompt templates, agent configs) without abandoning relational integrity.
- pgvector for embeddings-no extra cluster required up to ~100M vectors.
- Materialized views and realtime channels for dashboards.
Typical schema patterns
tenants,users,user_tenants(role mapping),documents,document_chunks,agent_runs,tool_invocations.tenant_settingsstores plan flags, rate limits, and feature toggles consumed by middleware and RAG pipelines.- Partition large tables (logs, tool metrics) by month or tenant to control costs.
Edge functions vs serverless runtimes
- We use Supabase Edge Functions for simple webhooks (Clerk, Stripe) and background jobs that benefit from data locality.
- Next.js API routes handle more complex flows requiring Server Actions, streaming, or orchestrating third-party APIs.
Alternatives
- PlanetScale / MySQL: stellar failover but lacks RLS; requires custom logic for multi-tenancy.
- MongoDB Atlas: works for document-heavy apps, but vector search + RLS is less mature.
- DynamoDB: great for event-heavy workloads, but query ergonomics slow down product teams used to SQL.
2.3 AI/LLM layer (OpenAI + Anthropic + MCP)
We support both OpenAI and Anthropic because enterprise buyers often mandate multi-model support.
Integration patterns
- Server Actions invoke
openai.responsesoranthropic.messageswith streaming turned on; responses stream to React viaReadableStream. - Token accounting: wrap calls with analytics hooks that emit
{ tenant_id, model, tokens_in, tokens_out, cost_usd }to PostHog. - RAG orchestration: vector search (pgvector) + keyword fallback + reranking (Cohere, BGE) before context injection.
- Agents & MCP: for Anthropic tool use, we host Model Context Protocol servers on Vercel Edge Functions with signed manifests and per-tool rate limits.
Guardrails & moderation
- Combine OpenAI moderation API with custom regex/entropy detectors to catch secrets.
- Use Ada/GPT-4o mini for classification tasks (detecting intent, tenant context, or whether RAG is needed).
Alternatives
- Vertex AI / Bedrock: enterprises with heavy GCP/AWS investments may prefer them for data residency; we still call them from Next.js when required.
- Self-hosted open models: great for cost control but require dedicated ML ops-only choose if you have GPU ops expertise.
2.4 Infrastructure & operations (Vercel + Cloudflare + PostHog)
| Layer | Why | Notes |
|---|---|---|
| Vercel | Preview deployments, Serverless/Edge runtime parity, secrets management, analytics. | Map to Vercel Projects per environment (dev/stage/prod). |
| Cloudflare Workers / Zero Trust | Harden API ingress, rate limit at the edge, and run lightweight tasks close to the user. | Use Cloudflare as API gateway when clients need allowlists. |
| Observability (PostHog + Datadog + Sentry) | Track tenant usage, token spend, LCP/CLS, and backend metrics. | PostHog event captures feed billing + abuse detection. |
| CI/CD (GitHub Actions) | Run RLS tests, lint, Playwright, and security scans before merging. | Use Vercel’s GitHub app for automatic previews. |
Deployment flow: PR opens → GitHub Actions run tests → Vercel builds preview → stakeholders review → merge triggers production deploy. Rollbacks happen via Vercel “Revert to Deployment” with environment secrets intact.
3. Architecture patterns on this stack
3.1 Multi-tenant SaaS foundation
- Auth & org switching: Clerk Organizations manage membership; Next.js middleware stores
activeTenantIdin encrypted cookies. - Tenant context injection: API routes read
x-tenant-id, set Postgresapp.current_tenant, and enforce RLS before queries. Supabase policies ensure even background jobs respect tenant boundaries. - Per-tenant caching: reuse Next.js
cachebut include tenant ID in keys; for Redis caches, namespace keys (tenant:123:recentDocs). - Audit logging: PostHog events + Postgres
tool_invocationstable maintain traceability for audits.
3.2 RAG retrieval flow
Ingestion → Chunking → Embedding (pgvector) → Keyword index → Hybrid search → Rerank → Guardrails → Streaming response
- Ingestion runs via queue workers (Supabase Edge or Inngest) reading from file uploads, CMS, or APIs.
- Hybrid search merges vector and keyword results before reranking (Cohere Rerank or BGE).
- Guardrails enforce tenant IDs, document freshness, and DLP filtering before context hits the LLM.
- Responses stream through Server Components; frontends show citations referencing
document_chunks.
3.3 Agent orchestration
- Tool registry stored in Postgres with schemas validated by Zod; Next.js server registers permitted tools per session.
- Execution service runs on Vercel serverless functions calling downstream APIs (Salesforce, HubSpot, Stripe).
- MCP server sits in front of internal APIs when using Anthropic tools; requires OAuth2 tokens per tenant.
- Observability: every tool call emits logs to PostHog for latency + abuse detection; Datadog monitors error rates.
3.4 Security overlay
- Edge middleware enforces zero-trust (JWT validation, IP allowlists) before requests reach APIs.
- Supabase RLS + Postgres policies act as safety net.
- Prompt injection defense handled by shared libraries (sanitization, output filtering) imported into Next.js Server Actions-reference the LLM Security Guide for details.
4. Real-world considerations
4.1 Performance tuning
- Cache embeddings and retrieval results per tenant to avoid redundant pgvector queries.
- Use Vercel Edge to terminate WebSockets/WebRTC near the user; fall back to serverless for CPU-heavy tasks.
- Optimize Next.js route handlers with
export const runtime = 'edge'when feasible to reduce cold starts. - Monitor Postgres index bloat; run
VACUUM/REINDEXfor vector-heavy tables.
4.3 Common pitfalls
- Forgetting to enable RLS on new tables.
- Storing OpenAI keys in client-side code (use Server Actions only).
- Overusing vector DBs for everything-some queries still need keyword search or relational joins.
- Neglecting cost alerts; token usage can spike during red-teaming.
- Shipping MCP/agent features without RBAC (tools become public inadvertently).
4.4 Migration scenarios
- From Rails/Monoliths: start by proxying requests to new Next.js features while keeping legacy auth. Use Supabase as a sidecar DB, migrate tables gradually.
- From Python/FastAPI: keep inference services in Python but move orchestration/UI to Next.js; use Inngest or Temporal to bridge runtimes.
- From static marketing sites: adopt Astro/Contentlayer for marketing, Next.js for apps; share Tailwind tokens for consistent branding.
4.5 Team velocity
- Next.js + shadcn enables designers and engineers to collaborate without blocking each other-components ship as documented primitives.
- Supabase dashboard + SQL editors allow quick data inspections during QA.
- Vercel previews mean stakeholders review features without staging environments.
5. Alternative stacks & when to choose them
| Stack | When it wins | Trade-offs |
|---|---|---|
| Python (FastAPI + PostgreSQL + AWS) | Data science-heavy teams with existing Python expertise. | Slower front-end velocity, more DevOps overhead, streaming UX harder without React Server Components. |
| Cloudflare-first (Workers + D1 + KV + AI Gateway) | Ultra-low latency edge use cases, lightweight chatbots, global consumer apps. | Still emerging RDBMS features; multi-tenant RLS patterns less mature. |
| AWS-native (Amplify + AppSync + DynamoDB + Bedrock) | Enterprises deep in AWS compliance/regionalization. | More moving parts, higher operational overhead, less developer ergonomics. |
| Ruby on Rails + Hotwire | Teams prioritizing CRUD dashboards with minimal AI features. | Streaming AI + agent tooling requires custom plumbing; TypeScript libraries may lag. |
We occasionally mix stacks (e.g., Python inference microservices with Next.js frontends) but keep the platform control plane on Next.js/Supabase for consistency.
6. Decision framework
Ask these questions when choosing your AI platform stack:
- What’s your multi-tenant strategy? If RLS and org switching are mandatory, Postgres-based stacks simplify life.
- How real-time is your UX? Streaming AI and collaborative dashboards benefit from React Server Components + Edge runtimes.
- Do you need deep compliance controls? Vercel + Supabase cover SOC/ISO needs for most startups; bespoke FedRAMP/HIPAA may push you toward dedicated VPCs.
- How heterogeneous is your AI layer? If you expect to swap models frequently, pick a stack with first-class Server Actions and secrets management (Next.js + Vercel).
- What’s your team’s expertise? Choose the stack that aligns with existing TypeScript/React or Python talent; avoid splitting teams across paradigms unnecessarily.
7. FAQ: AI Platform Development Stack
Why Next.js over other frameworks? Next.js offers the best combination of features for AI platforms: Server Components for streaming AI responses, Edge Runtime for low-latency, built-in API routes, excellent TypeScript support, and massive ecosystem. Most importantly, it handles both complex dashboards and high-performance AI features without forcing you to maintain separate codebases.
Can I use this stack without Vercel? Yes. Next.js runs on any Node.js host (Railway, Fly.io, self-hosted). However, Vercel provides significant advantages: zero-config Edge Functions, instant preview deployments, built-in CDN, and excellent monitoring. For most teams, Vercel’s developer experience justifies the cost.
What about Python for AI development? Python excels for data science and ML training, but for production AI applications with real-time UX, Next.js/TypeScript wins. That said, many teams use hybrid approaches: Python microservices for inference, Next.js for the application layer. We can help architect either approach.
Is this stack suitable for enterprise? Yes. Vercel Enterprise + Supabase Pro provides: SOC 2 Type II, HIPAA compliance options, SSO/SAML, advanced DDoS protection, dedicated support, and SLAs. We’ve deployed this stack for regulated industries including healthcare and finance.
What if we need different AI models? The stack is model-agnostic. Swap between OpenAI, Anthropic, Cohere, Mistral, or self-hosted models without architectural changes. Use Vercel’s built-in model proxy or AI SDK for seamless switching.
How long does it take to build on this stack?
- MVP: 4-8 weeks (basic auth, simple AI features)
- Production-ready: 8-16 weeks (multi-tenancy, security, compliance)
- Enterprise platform: 16-24 weeks (advanced features, integrations, scale testing)
Timelines vary based on feature complexity and team size.
Ready to build your AI platform?
Next.js, Supabase, and Vercel give AI product teams security-first multi-tenancy, fast iteration cycles, native RAG + agent support, and production-grade observability. We’ve battle-tested this stack on SaaS platforms, internal tooling, and public-facing AI products.
Option 1: Stack Architecture Assessment
2-hour review of your requirements and tech stack recommendation tailored to your use case, team, and timeline.
What’s included:
- Requirements and use case analysis
- Stack recommendation (Next.js vs alternatives)
- Architecture diagram and data flow
- Cost estimates at different scales
- Timeline and team size projections
- Technology evaluation (databases, hosting, AI providers)
Option 2: AI Platform MVP Development
Build your AI platform MVP in 4-8 weeks with core features and best practices.
What’s included:
- Next.js application setup with App Router
- Supabase database and authentication
- Basic multi-tenancy (org switching)
- AI integration (chat, completions, or RAG)
- Modern UI with shadcn components
- Vercel deployment
- Basic monitoring and analytics
- Documentation
Option 3: Production AI Platform (Most Popular)
Full-featured, production-ready AI platform with security, scalability, and compliance.
What’s included:
- Everything in MVP, plus:
- Row-level security (RLS) and tenant isolation
- RAG pipeline with pgvector
- AI agent system with tool orchestration
- Advanced authentication (SSO, MFA, RBAC)
- Billing integration (Stripe/usage-based)
- Comprehensive testing suite
- Security hardening and structured security testing
- Observability (PostHog, Sentry, custom dashboards)
- Compliance prep (SOC 2, ISO 27001)
- 30-day post-launch support
Option 4: Enterprise AI Platform
Large-scale platform with advanced features, integrations, and enterprise requirements.
Best for:
- Regulated industries (healthcare, finance)
- Complex multi-tenant architectures
- Advanced AI capabilities (multi-agent, custom models)
- Multiple integration requirements
- High-scale performance requirements
Not sure which option fits?
Book a free 30-minute consultation to review your requirements and get personalized recommendations.
Free resources:
- AI Platform Architecture Checklist - Complete security-first architecture scorecard
Related resources:
- Multi-Tenant SaaS Architecture - RLS and data modeling patterns
- RAG Architecture Guide - Retrieval pipeline implementation
- AI Agent Architecture - Agent orchestration and MCP
- AI Platform Security Guide - Security framework
Ready to design your stack? Let’s talk.


