Services / AI Platform Development
Production AI Platforms — Agents, Orchestration & Retrieval
One team owns ingestion, retrieval, LLM orchestration, identity, billing, and security testing — so your platform ships without surprises. Next.js frontends with Python backends, or full-stack TypeScript. Your call.
Typical delivery
6-8 weeks · Weekly checkpoints · Full-stack + security under one roof
- Agent orchestration, retrieval pipelines, or both
- Multi-tenant auth, billing, and usage metering
- Security testing and compliance artifacts
- Eval harnesses, observability dashboards, and runbooks
What we build
Agent orchestration, RAG implementation, multi-tenant architecture, and Python backends — all inside the same sprint. No handoffs between specialists.
Platform Deliverables
Every engagement includes the components required to harden an AI platform for launch: ingestion, hybrid retrieval, guardrails, monitoring, and security testing.
Process
How We Build & Secure AI Platforms
No agency relay race. One team owns discovery, architecture, development, and security testing so timelines don't slip and findings come with fixes.
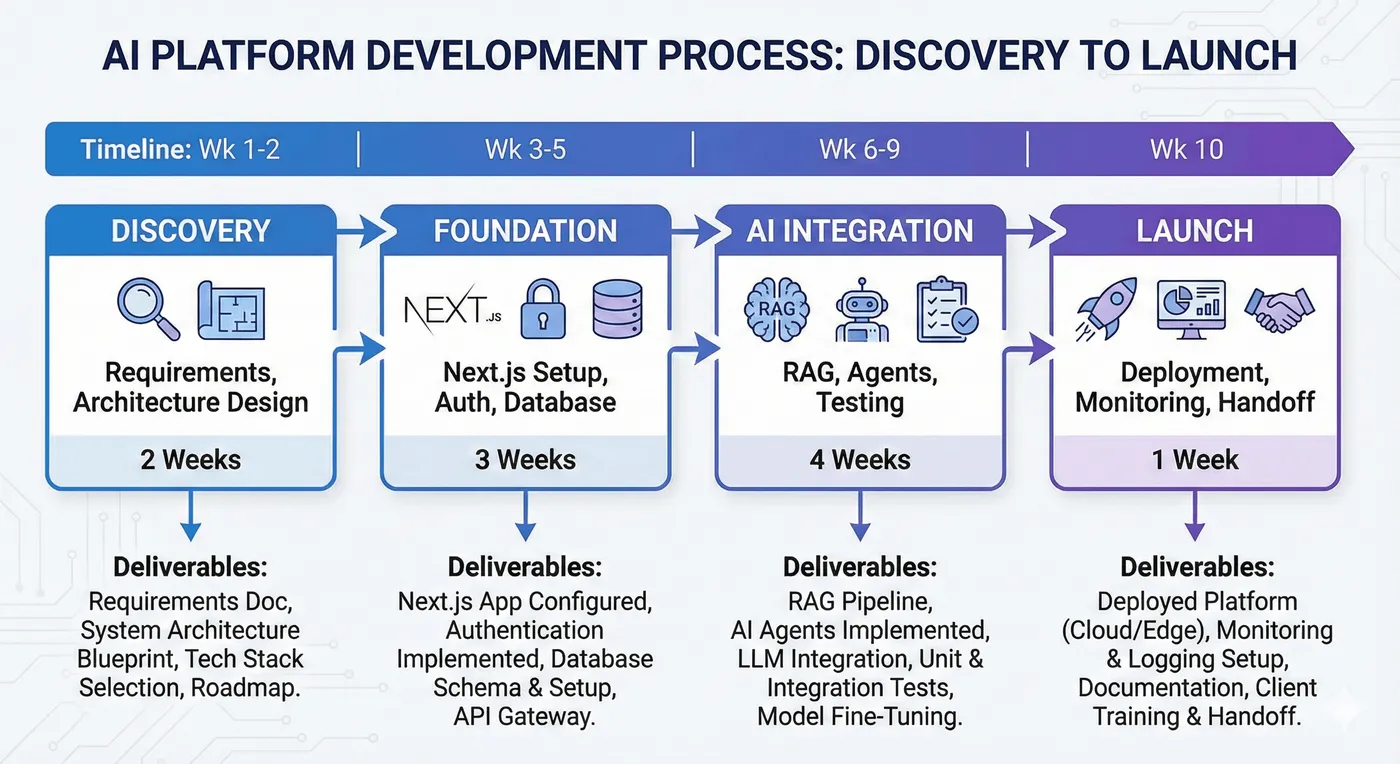
- 01 - Discovery & audit. Review documents, security questionnaires, and target UX. Establish golden question set.
- 02 - Architecture & ingestion. Stand up pipelines, metadata, and background workers with monitoring.
- 03 - Retrieval & orchestration. Implement hybrid search, reranking, LLM prompts, and prompt-injection guardrails.
- 04 - Hardening & launch. Security testing, eval harnesses, handover docs, and runbooks.
- Next.js 16+ / ShadCN UI / Vercel Edge
- Python 3.12+ / FastAPI / Celery / Temporal
- Neon or Supabase with pgvector
- Clerk orgs, SSO/SAML, SCIM
- Stripe Billing + usage ledgers
- Anthropic Claude / OpenAI orchestration
- PostHog analytics & feature flags
- PyTorch / LoRA / ONNX for custom models
- • 6-8 weeks for most builds (scales with complexity)
- • Weekly working sessions to review progress
- • Staging env live early in the engagement
- • Security testing baked into every sprint
- • Cancel anytime with 2 weeks notice
Recent builds
Proof this model works
Fintech RAG Launch
6 critical vulns patched pre-audit
- Multi-tenant RAG had tenant isolation bug — caught during Week 4 testing.
- Missing rate limits on inference APIs — fixed before onboarding banks.
- Passed bank security review on the first attempt with zero findings.
Agent Operations Platform
25 workflows live, 0 regressions
- MCP servers with tool allowlists + audit logging shipped Week 6.
- Credential misuse caught during testing — blocked by the policy engine.
- Adoption + cost dashboards ready for Series A investor demos.
Multi-tenant SaaS Modernization
Zero findings on external pen test
- Rails/Next.js upgrade with RAG knowledge base and Stripe metering.
- 800+ automated tests caught regressions before production.
- Support backlog dropped 40% once AI summaries landed.
FAQ
Common Questions
What do engagements include?
Every build covers ingestion, embeddings, hybrid retrieval, LLM orchestration, observability, billing, and security testing. You get architecture, code, eval harnesses, and runbooks — not just a demo.
Do you handle frontend and backend?
Yes. Next.js for dashboards and customer-facing UX, Python (FastAPI/Django) for data pipelines and ML infrastructure. Same team, no handoffs.
How fast can you deliver production systems?
Most builds ship in 6-8 weeks. Discovery, architecture, and a staging environment come first, then retrieval, orchestration, and security testing ramp in parallel.
What testing coverage do you provide?
Playwright E2E tests, Vitest/pytest suites, and security testing (OWASP ZAP, prompt injection suites). We target 80%+ coverage and zero critical findings before launch.
Do you only work with Bay Area teams?
Most engagements are remote-friendly. Slack, Loom, and weekly working sessions keep teams in sync regardless of timezone.
Ready to ship your AI platform?
Whether you need an MVP, platform scale-out, or architecture review, you work directly with an AI architect who builds and secures the entire stack.
Serving companies across the San Francisco Bay Area, Silicon Valley, and remote teams worldwide.